Charts Library¶
Vincent provides a charts library that allows for rapid creation and iteration of different chart types, with data inputs from a number of Python data structures. This library is built using the Vincent API to construct Vega grammar, with some adding conveniences for simple data input.
Chart¶
The Chart class is a base container for ingesting data and creating a Vega scaffold:
>>>chart = vincent.Chart([10, 20, 30, 40, 50])
>>>chart.grammar()
{u'axes': [],
u'data': [{u'name': u'table',
u'values': [{u'col': u'data', u'idx': 0, u'val': 10},
{u'col': u'data', u'idx': 1, u'val': 20},
{u'col': u'data', u'idx': 2, u'val': 30},
{u'col': u'data', u'idx': 3, u'val': 40},
{u'col': u'data', u'idx': 4, u'val': 50}]}],
u'height': 300,
u'legends': [],
u'marks': [],
u'padding': {u'bottom': 50, u'left': 50, u'right': 100, u'top': 10},
u'scales': [],
u'width': 500}
Note the use of chart.grammar() to output the specification to Python data structures. If at any point you wish to view the current specification, use the grammar() call. This works at almost any level of nesting depth as well:
>>>chart.data[0].grammar()
{u'name': u'table',
u'values': [{u'col': u'data', u'idx': 0, u'val': 10},
{u'col': u'data', u'idx': 1, u'val': 20},
{u'col': u'data', u'idx': 2, u'val': 30},
{u'col': u'data', u'idx': 3, u'val': 40},
{u'col': u'data', u'idx': 4, u'val': 50}]}
Charts will take a number of different data sources. All of the following produce equivalent data output:
list_data = [10, 20, 30, 40, 50]
dict_of_iters = {'x': [0, 1, 2, 3, 4], 'data': [10, 20, 30, 40, 50]}
series = pd.Series([10, 20, 30, 40, 50])
dataframe = pd.DataFrame({'data': [10, 20, 30, 40, 50]})
#All of the following are equivalent
chart = vincent.Chart(list_data)
chart = vincent.Chart(dict_of_iters, iter_idx='x')
chart = vincent.Chart(series)
chart = vincent.Chart(dataframe)
vincent.Chart is the abstract base class on which all other chart types are built.
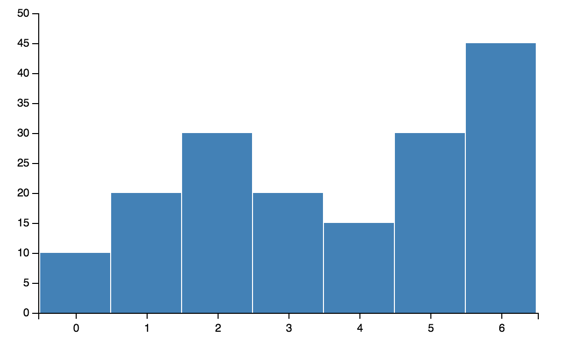
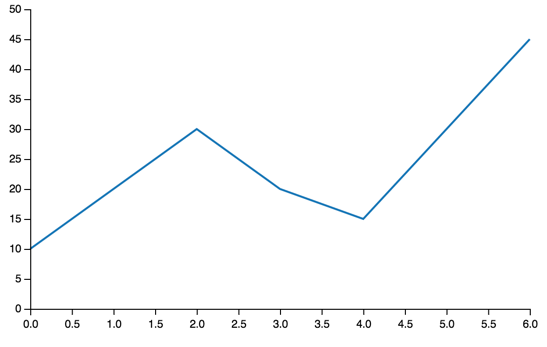
Line¶
Similar to bar, you can plot just one line:
line = vincent.Line([10, 20, 30, 20, 15, 30, 45])
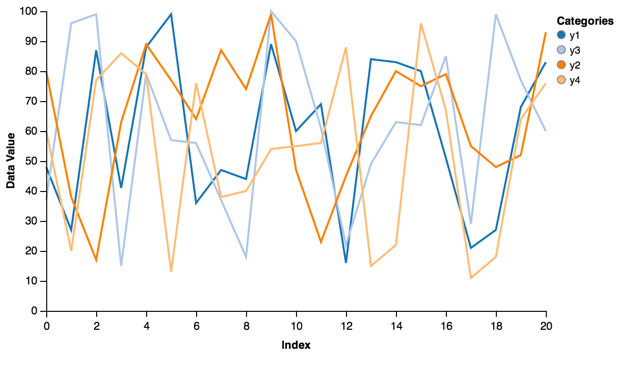
Multiple lines can also be plotted easily:
cats = ['y1', 'y2', 'y3', 'y4']
index = range(1, 21, 1)
multi_iter1 = {'index': index}
for cat in cats:
multi_iter1[cat] = [random.randint(10, 100) for x in index]
lines = vincent.Line(multi_iter1, iter_idx='index')
lines.legend(title='Categories')
lines.axis_titles(x='Index', y='Data Value')
You can also specify the x-coordinates explicitly:
vincent.Line({i: math.sin(i/15.0) for i in range(10, 100, 2)})

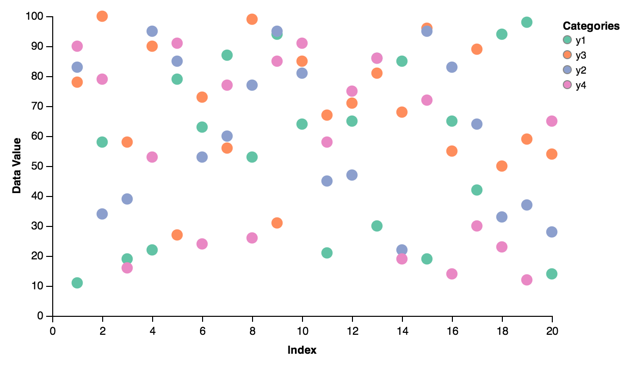
Scatter¶
Using the same data from above, with some different color choices:
scatter = vincent.Scatter(data, iter_idx='index')
scatter.axis_titles(x='Index', y='Data Value')
scatter.legend(title='Categories')
scatter.colors(brew='Set2')
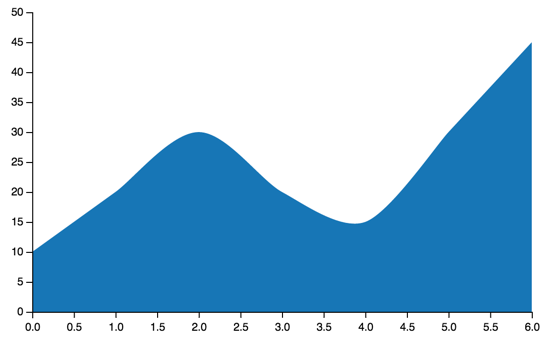
Area¶
Area charts are basically an extension of Line:
area = vincent.Area([10, 20, 30, 20, 15, 30, 45])
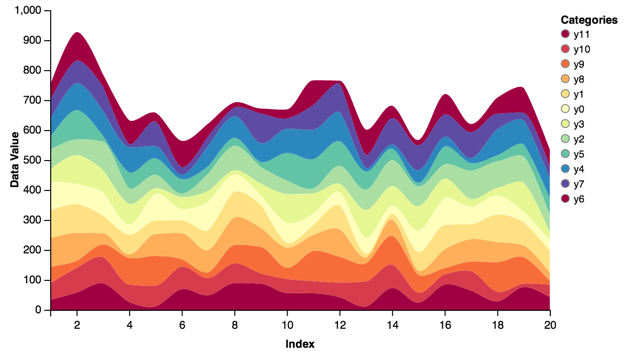
Stacked Area¶
Stacked areas allow you to visualize multiple pieces of data with an area-type chart. Lets look at a large number of categories:
cats = ['y' + str(x) for x in range(0, 12, 1)]
index = range(1, 21, 1)
data = {'index': index}
for cat in cats:
data[cat] = [random.randint(10, 100) for x in index]
stacked = vincent.StackedArea(data, iter_idx='index')
stacked.axis_titles(x='Index', y='Data Value')
stacked.legend(title='Categories')
stacked.colors(brew='Spectral')
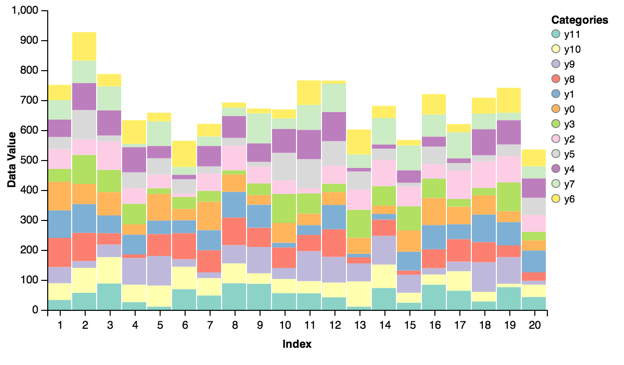
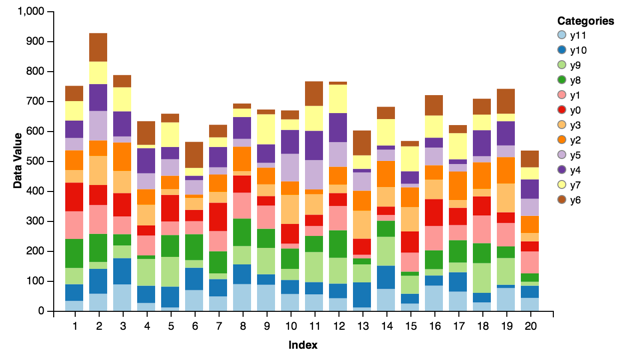
Stacked Bar¶
A variation that allows you to stack bars similar to areas for ordinal quantities. Using the data from above:
stacked = vincent.StackedBar(data, iter_idx='index')
stacked.axis_titles(x='Index', y='Data Value')
stacked.legend(title='Categories')
stacked.colors(brew='Set3')
For bar charts with large numbers of bars, its often useful to pad each bar:
stacked.scales['x'].padding = 0.2
stacked.colors(brew='Paired')
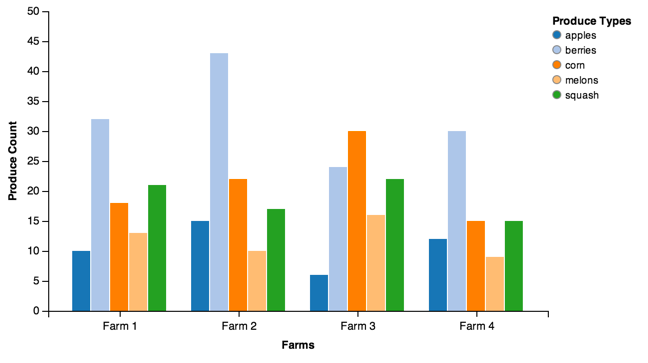
Grouped Bar¶
It’s often useful to plot bars with quantities associated with different groups. For example, produce output at different farms:
import pandas as pd
farm_1 = {'apples': 10, 'berries': 32, 'squash': 21, 'melons': 13, 'corn': 18}
farm_2 = {'apples': 15, 'berries': 43, 'squash': 17, 'melons': 10, 'corn': 22}
farm_3 = {'apples': 6, 'berries': 24, 'squash': 22, 'melons': 16, 'corn': 30}
farm_4 = {'apples': 12, 'berries': 30, 'squash': 15, 'melons': 9, 'corn': 15}
data = [farm_1, farm_2, farm_3, farm_4]
index = ['Farm 1', 'Farm 2', 'Farm 3', 'Farm 4']
df = pd.DataFrame(data, index=index)
grouped = vincent.GroupedBar(df)
grouped.axis_titles(x='Farms', y='Produce Count')
grouped.legend(title='Produce Types')
Currently grouped sets only work with Pandas DataFrames, but that should change soon. In the meantime, getting data into a DataFrame is straightforward:
cats = ['y' + str(x) for x in range(0, 10, 1)]
index = ['Data 1', 'Data 2', 'Data 3', 'Data 4']
data = {}
for cat in cats:
data[cat] = [random.randint(10, 100) for x in index]
df = pd.DataFrame(data, index=index)
grouped = vincent.GroupedBar(df)
grouped.width = 700
grouped.height = 250
grouped.colors(brew='Set3')
grouped.axis_titles(x='Dataset', y='Value')
grouped.legend(title='Data Category')

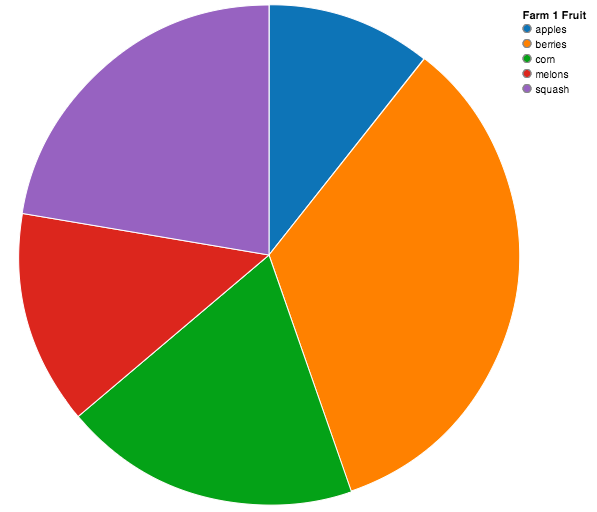
Pie/Donut Chart¶
Pie chart outer radius defaults to 1/2 min(width/height):
pie = vincent.Pie(farm_1)
pie.legend('Farm 1 Fruit')
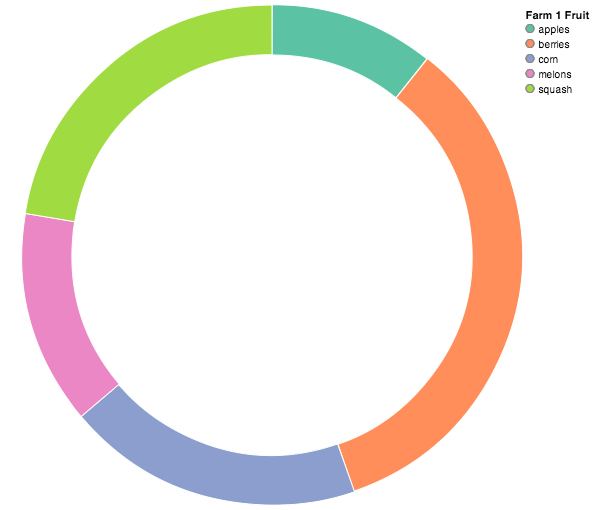
Donut charts can be created by passing an inner radius:
donut = vincent.Pie(farm_1, inner_radius=200)
donut.colors(brew="Set2")
donut.legend('Farm 1 Fruit')
Simple Map¶
You can find all of the TopoJSON data in the vincent_map_data repo.
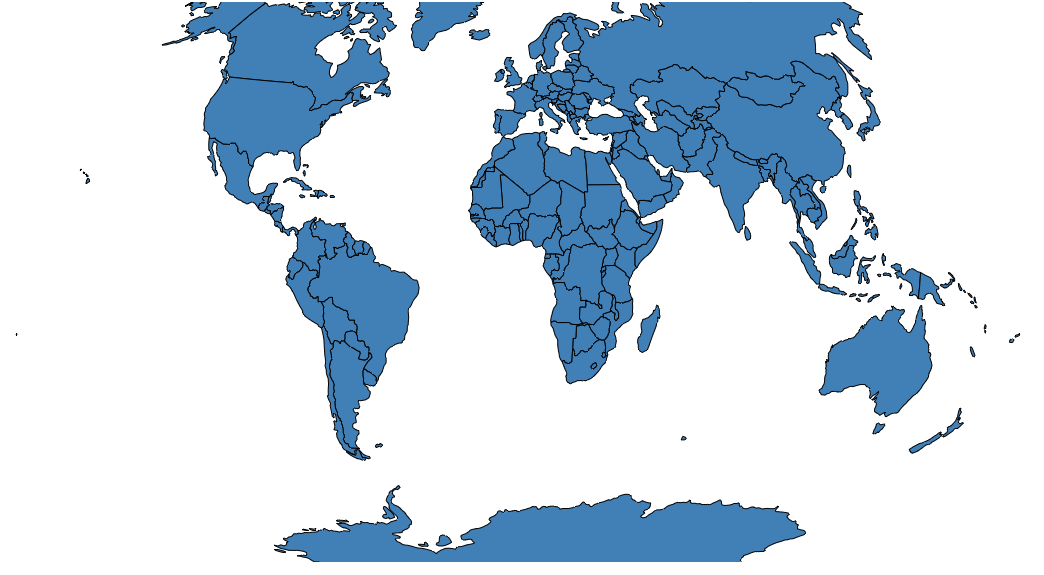
A simple world map:
world_topo = r'world-countries.topo.json'
geo_data = [{'name': 'countries',
'url': world_topo,
'feature': 'world-countries'}]
vis = Map(geo_data=geo_data, scale=200)
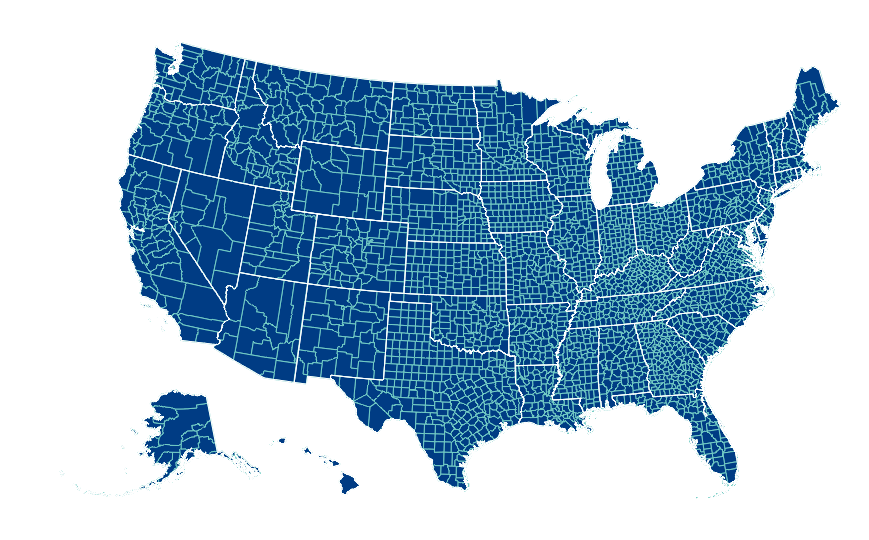
You can also pass multiple map layers:
geo_data = [{'name': 'counties',
'url': county_topo,
'feature': 'us_counties.geo'},
{'name': 'states',
'url': state_topo,
'feature': 'us_states.geo'}
]
vis = Map(geo_data=geo_data, scale=1000, projection='albersUsa')
del vis.marks[1].properties.update
vis.marks[0].properties.update.fill.value = '#084081'
vis.marks[1].properties.enter.stroke.value = '#fff'
vis.marks[0].properties.enter.stroke.value = '#7bccc4'
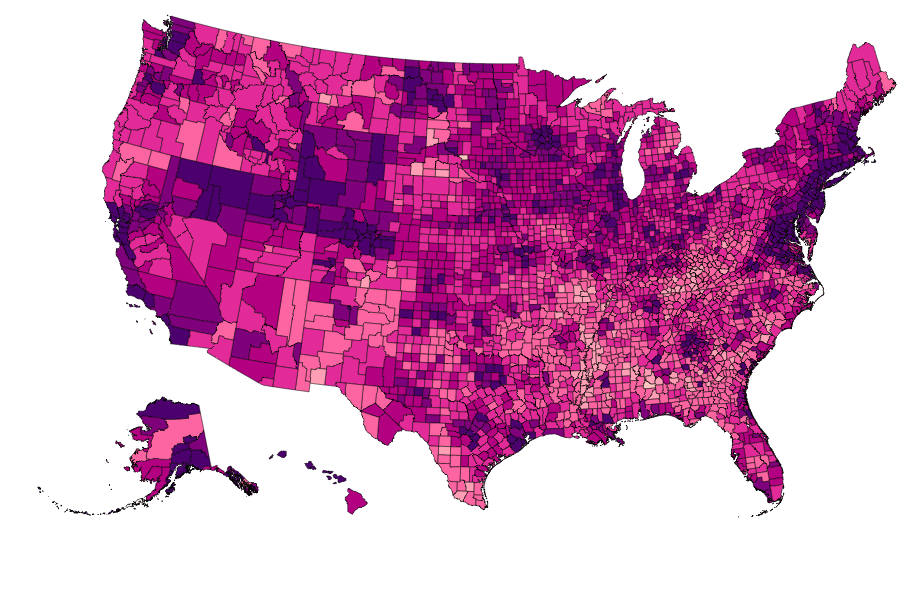
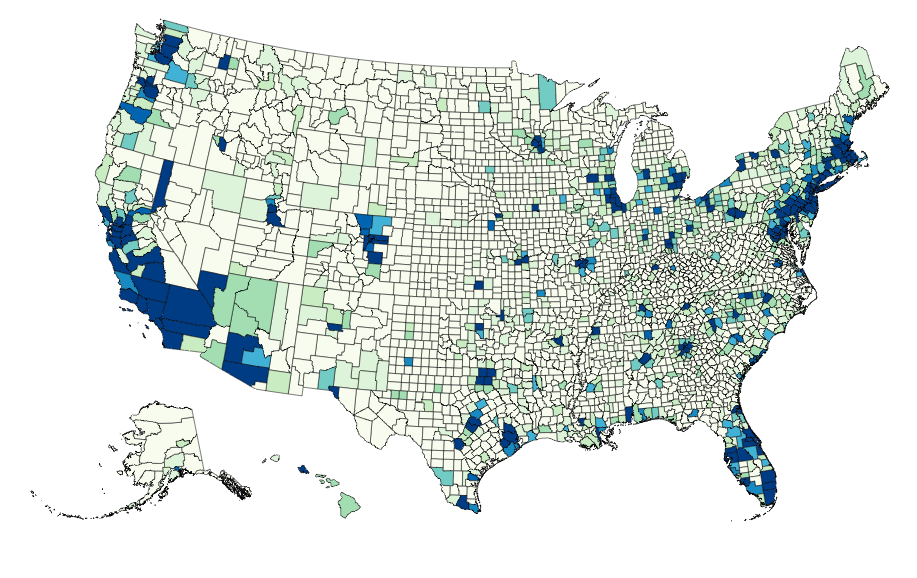
Map Data Binding¶
Maps can be bound to data via Pandas DataFrames to create Choropleths, with some data munging to match keys:
import json
import pandas as pd
#Map the county codes we have in our geometry to those in the
#county_data file, which contains additional rows we don't need
with open('us_counties.topo.json', 'r') as f:
get_id = json.load(f)
#A little FIPS code munging
new_geoms = []
for geom in get_id['objects']['us_counties.geo']['geometries']:
geom['properties']['FIPS'] = int(geom['properties']['FIPS'])
new_geoms.append(geom)
get_id['objects']['us_counties.geo']['geometries'] = new_geoms
with open('us_counties.topo.json', 'w') as f:
json.dump(get_id, f)
#Grab the FIPS codes and load them into a dataframe
geometries = get_id['objects']['us_counties.geo']['geometries']
county_codes = [x['properties']['FIPS'] for x in geometries]
county_df = pd.DataFrame({'FIPS': county_codes}, dtype=str)
county_df = county_df.astype(int)
#Read into Dataframe, cast to string for consistency
df = pd.read_csv('data/us_county_data.csv', na_values=[' '])
df['FIPS_Code'] = df['FIPS'].astype(str)
#Perform an inner join, pad NA's with data from nearest county
merged = pd.merge(df, county_df, on='FIPS', how='inner')
merged = merged.fillna(method='pad')
geo_data = [{'name': 'counties',
'url': county_topo,
'feature': 'us_counties.geo'}]
vis = Map(data=merged, geo_data=geo_data, scale=1100, projection='albersUsa',
data_bind='Employed_2011', data_key='FIPS',
map_key={'counties': 'properties.FIPS'})
vis.marks[0].properties.enter.stroke_opacity = ValueRef(value=0.5)
vis.to_json('vega.json')
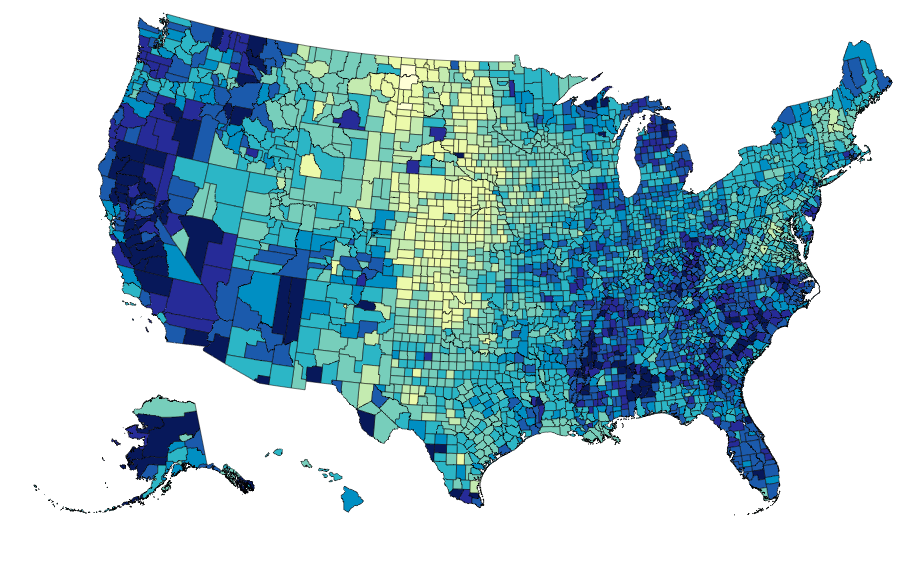
The data can be rebound for new columns with different color brewer scales on the fly:
vis.rebind(column='Unemployment_rate_2011', brew='YlGnBu')
vis.to_json('vega.json')
vis.rebind(column='Median_Household_Income_2011', brew='RdPu')
vis.to_json('vega.json')